

What Were Google Cached Pages?
Google cached pages were Google’s records of how pages looked when they were last indexed.
You could access a cached page by doing a Google search for the page’s URL. And clicking the three vertical dots next to its search result on the search engine results page (SERP).
An “About this result” panel providing more information about the page would appear. You could then click the panel’s “Cached” link button:
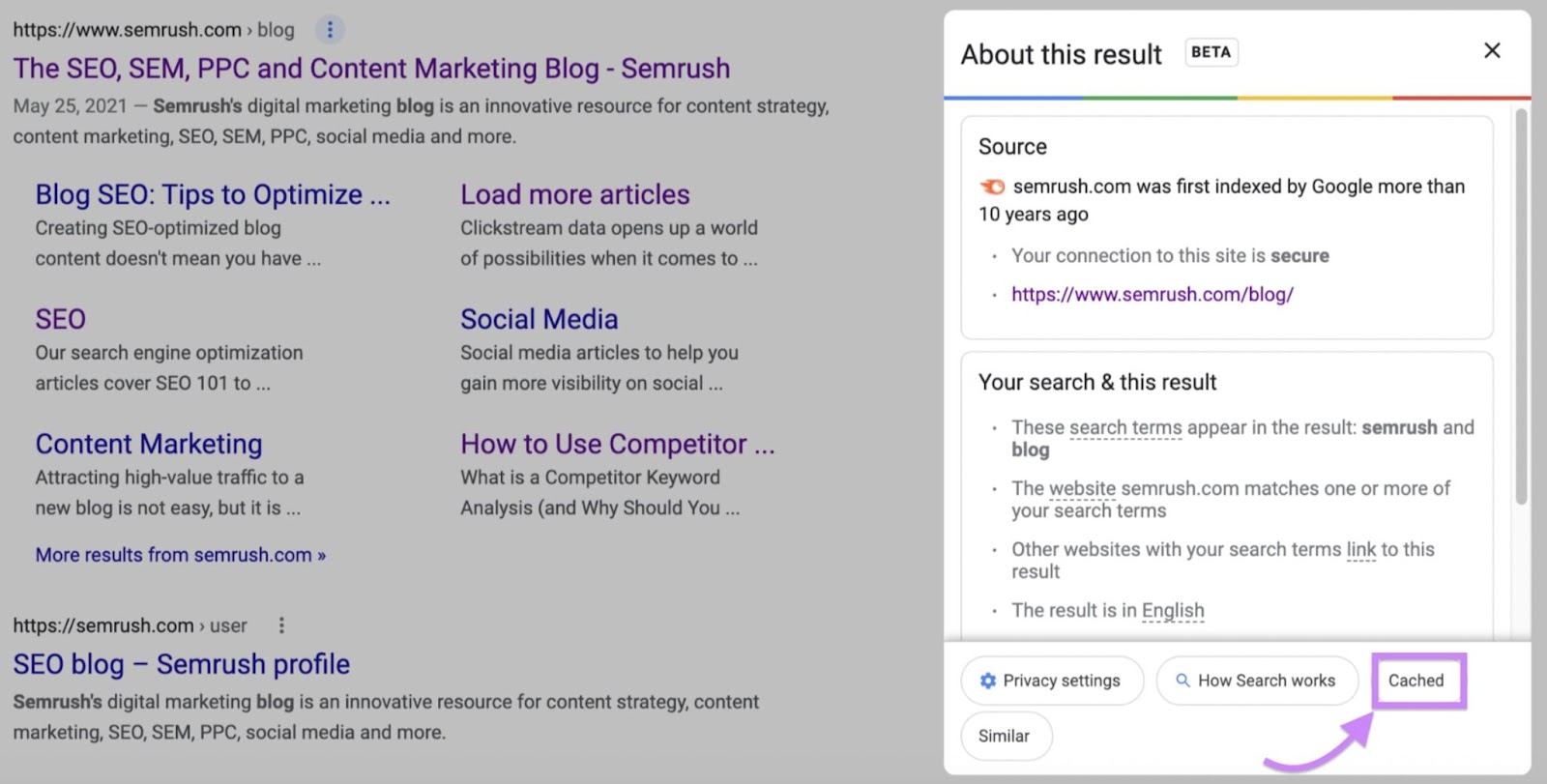
And Google would show you its cached version of the page as of a certain date and time.
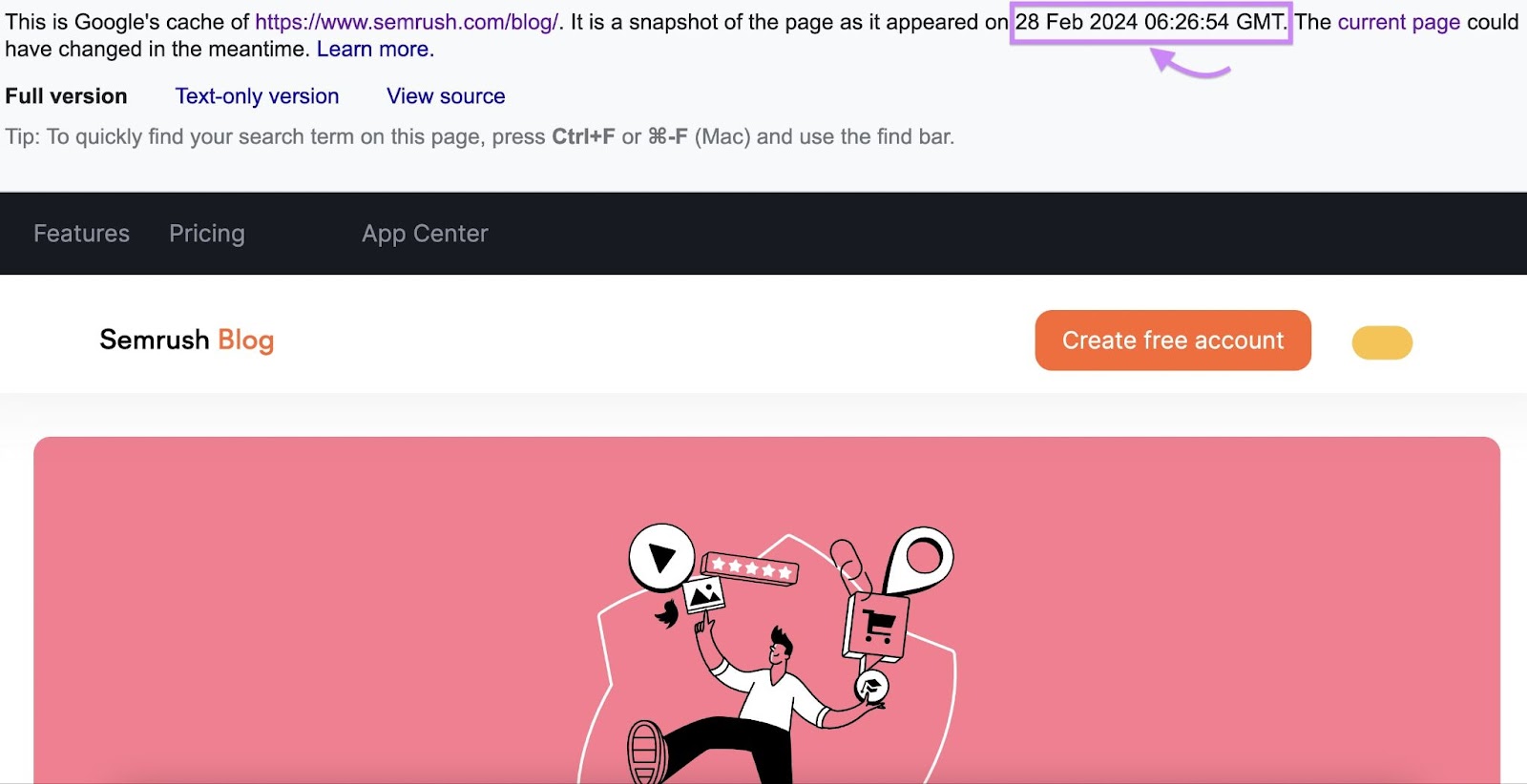
You could also access Google’s cached version of a page by adding “cache:” before the page’s URL in your browser address bar.
Like so:

In February 2024, Google confirmed its removal of the “Cached” link button from its search results’ “About this result” panels. As a result, users can no longer access Google’s cached pages from its SERPs.
Adding “cache:” before the page’s URL in your address bar still works. But Google will also be disabling this feature soon.
Why did Google cache pages? Why is it removing access to them now? And what alternatives do you have, in light of this change?
Let’s find out.
The Rationale for Google Caching
Google’s “cached” feature was more than 20 years old.
Here’s how the Google SERP looked on Dec. 3, 2000, for example. Check out the “Cached” link for each search result:
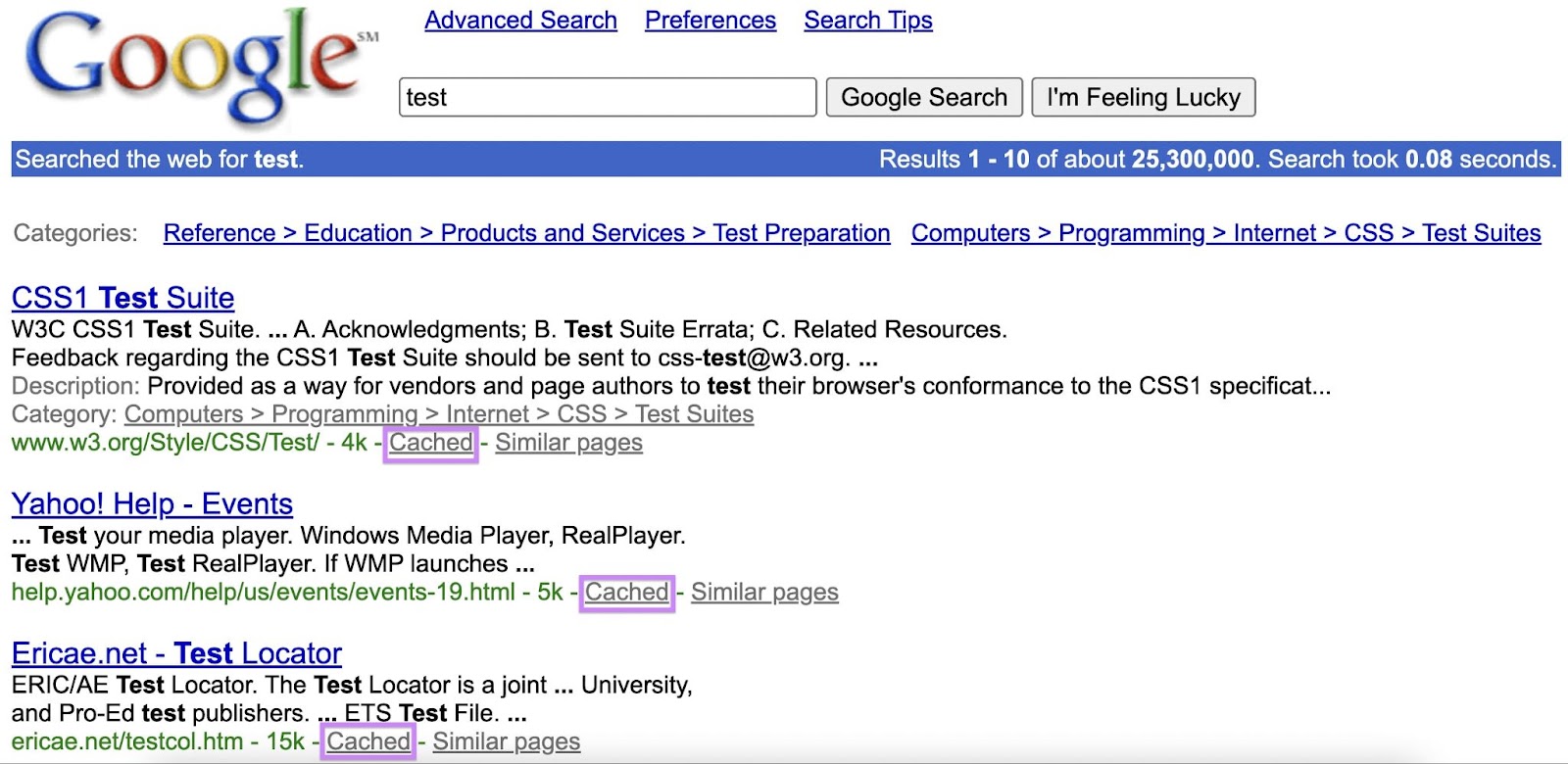
And over these past 20-plus years, the feature played an important role.
Why Did Google Cache Pages at All?
Google cached pages to help users view unavailable webpages.
These pages could be unavailable due to reasons like:
- The website’s server was down
- The website’s server was overloaded with traffic
- The page was taking too long to load
So, if a user couldn’t access a page itself, they could view Google’s cached page instead. And get the information they wanted.
The Importance of Google Cached Pages to Website Owners
Google cached pages mainly for users’ benefit. But website owners could also use the cached pages to check whether Google had indexed their pages correctly.
When Google indexes a page, it saves a copy of the page in its search results database, or index—which is not publicly accessible. It also saved another copy of the page in its cache—which was publicly accessible.
Due to limitations in Google’s caching abilities, Google’s cached version of a page may not have been identical to the version of the page in Google’s index. But it was still a good approximation.
So, even though website owners couldn’t—and still can’t—check how their page looks in Google’s index, they could still check how it looked in Google’s cache. Doing this, they’d get guidance on how the search engine saw their page when indexing it.
If Google’s cached version of the page looked significantly different from what the website owner intended, its indexed counterpart might not be what they intended, either.
The website owner could then take action to improve their page. And have Google reindex it after that.
That way, Google would update the version of the page in its index, and display that updated page in response to relevant search queries.
The Discontinuation of Access to Google Cached Pages
Google Search Liaison Danny Sullivan confirmed in an X (formerly Twitter) post on February 2, 2024, that the search engine had removed the “Cached” links from its SERPs:
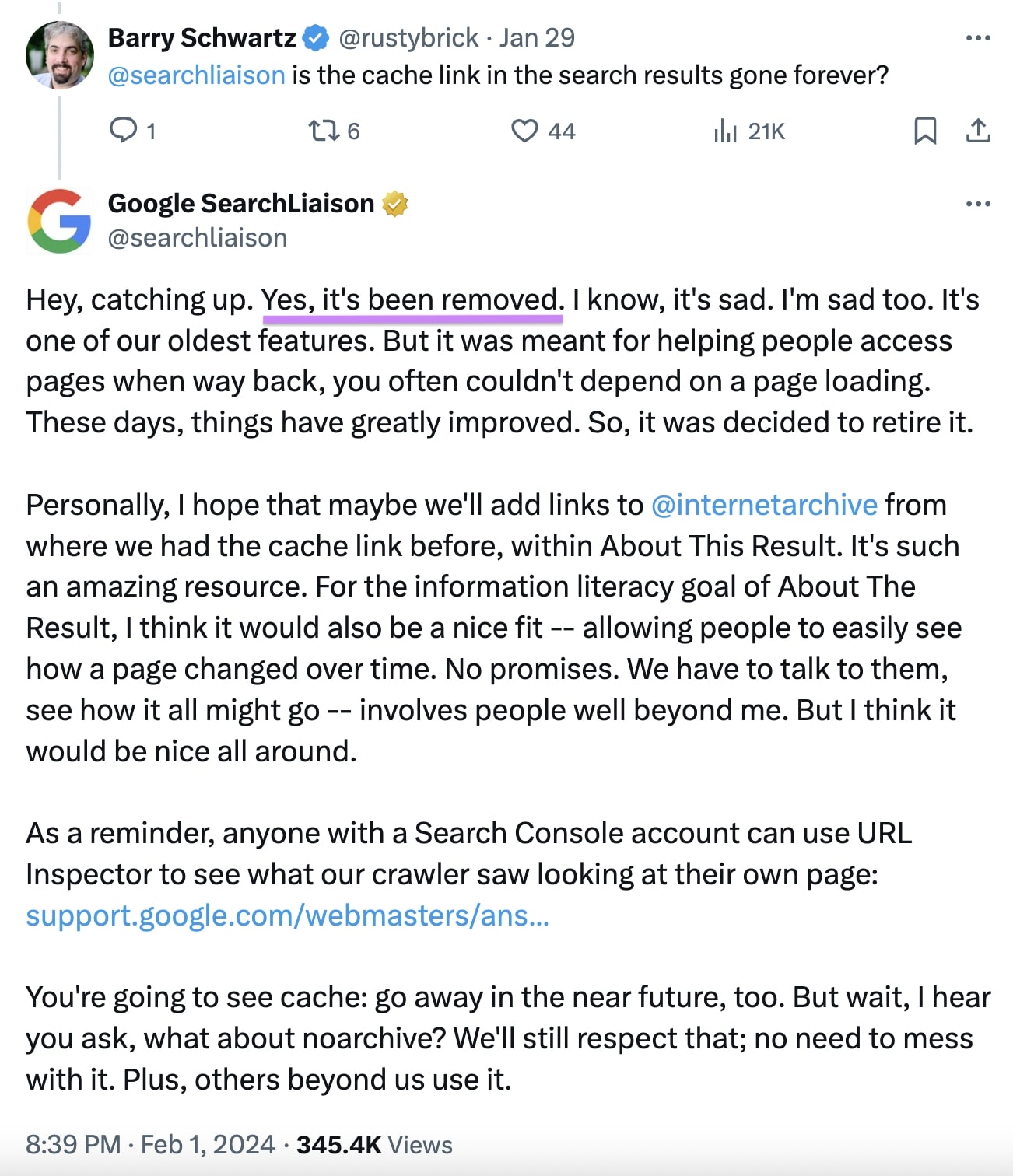
In the post, Sullivan explained that Google originally provided the feature more than 20 years ago to help users access pages.
At that time, website technology was more primitive. And internet speeds were slower.
The result?
Websites didn’t always load reliably.
But technology has improved over the years. Now, Google believes users face fewer issues trying to visit websites.
So, it decided to discontinue its “Cached” links. It will also “in the near future” prevent users from using the “cache:” method to access its cached pages.
Impact of Discontinuing Access to Google Cached Pages
Google’s decision to remove access to its cached pages will affect various stakeholders:
Users
Users won’t be able to use Google’s “cached” feature to:
- View unavailable pages. They can’t click the page’s “Cached” link on the Google SERP to access its cached version.
- Bypass article paywalls. Users could previously use the cached pages to read certain paywalled articles for free. But not anymore.
SEO Professionals
SEO professionals may encounter more difficulty:
- Checking whether Google has appropriately indexed their page
- Checking when Google last indexed their page. They can no longer get this information by referring to the cached version’s timestamp.
- Conducting competitor research. E.g., comparing a competitor’s live page with its cached version to identify changes to its content. Especially if the competitor’s page had recently gotten a big rankings boost.
- Identifying deceptive cloaking activity. A website owner may have given search engines one version of a page to index and rank and used redirects to show users a significantly different page. If so, Google’s cached version of the page could uncover the deception by revealing what the search engine saw when indexing it.
Web Developers
Web developers will need alternative tools for:
- Recovering lost content. This could be content from a page that had gone down. Or content that they’d forgotten to back up before updating the page. Either way, they could have accessed Google’s cached version of the page—assuming it still contained the required content—to retrieve what had been lost.
- Troubleshooting website code. Web developers could use Google’s cached pages to check how the search engine rendered their webpages. Differences between the rendered and intended pages’ appearances could indicate code errors. Even if the website looked “normal” to users.
Alternatives to Google Cached Pages
Google’s “cached” feature isn’t the only option for viewing past versions of pages. Here are some alternatives.
URL Inspection Tool
The URL Inspection Tool is a Google Search Console (GSC) tool for getting information on your website’s Google-indexed pages. This information includes:
- The date and time Google last crawled (i.e., visited) the page
- Whether Google could index the page
- How Google saw the page when indexing it
The URL Inspection Tool provides more accurate insights into how Google has indexed a page than Google’s cached pages.
That’s because unlike Google’s caching features, the URL Inspection Tool doesn’t have trouble processing JavaScript code. So, it can more accurately show how Google sees your indexed page—especially if its appearance is influenced by JavaScript.
To use the URL Inspection Tool on your pages, log in to GSC. (Set up GSC on your website first if you haven’t already.)
There’s a search bar at the top of every GSC screen. Type—or copy and paste—the URL of the page you want to check.
Then, press “Enter” or “Return” on your keyboard.
Google will retrieve data on your page from its index. If it has indexed your page, you’ll see the message “URL is on Google.”
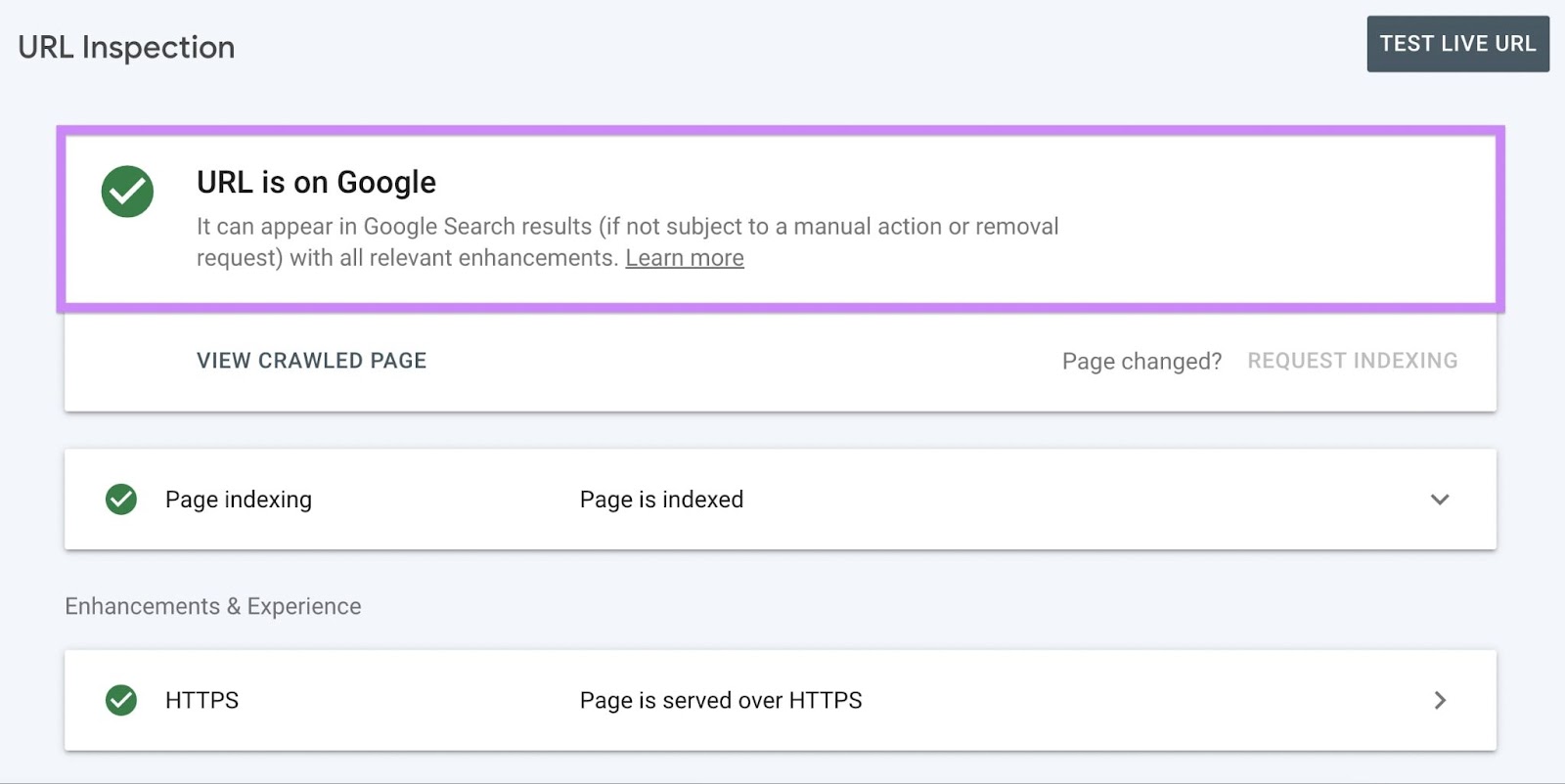
Click “View crawled page” to see the Hypertext Markup Language (HTML) Google has detected on your page.
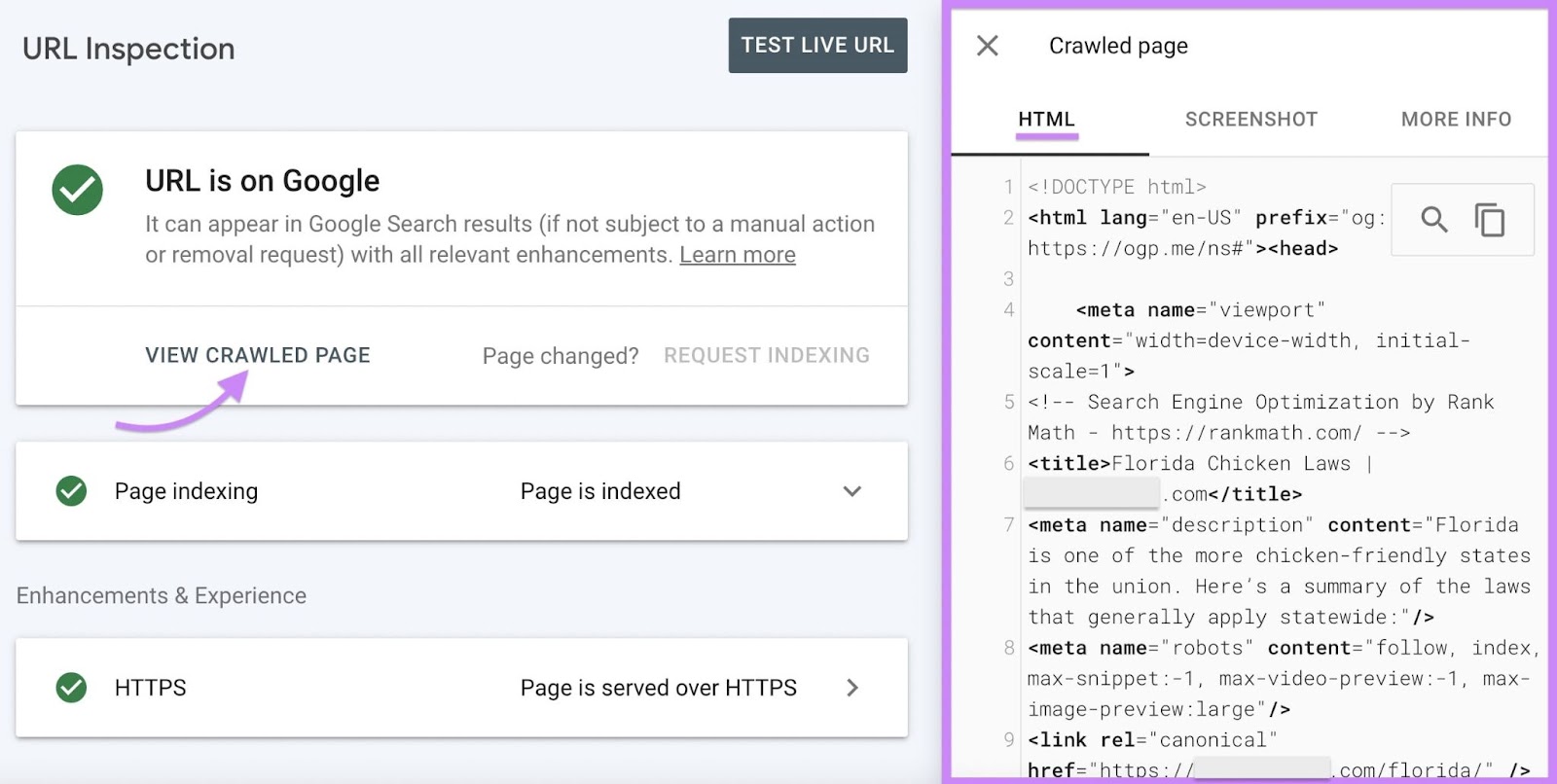
Alternatively, click the “Page indexing” drop-down menu to learn the date and time Google last crawled your page.
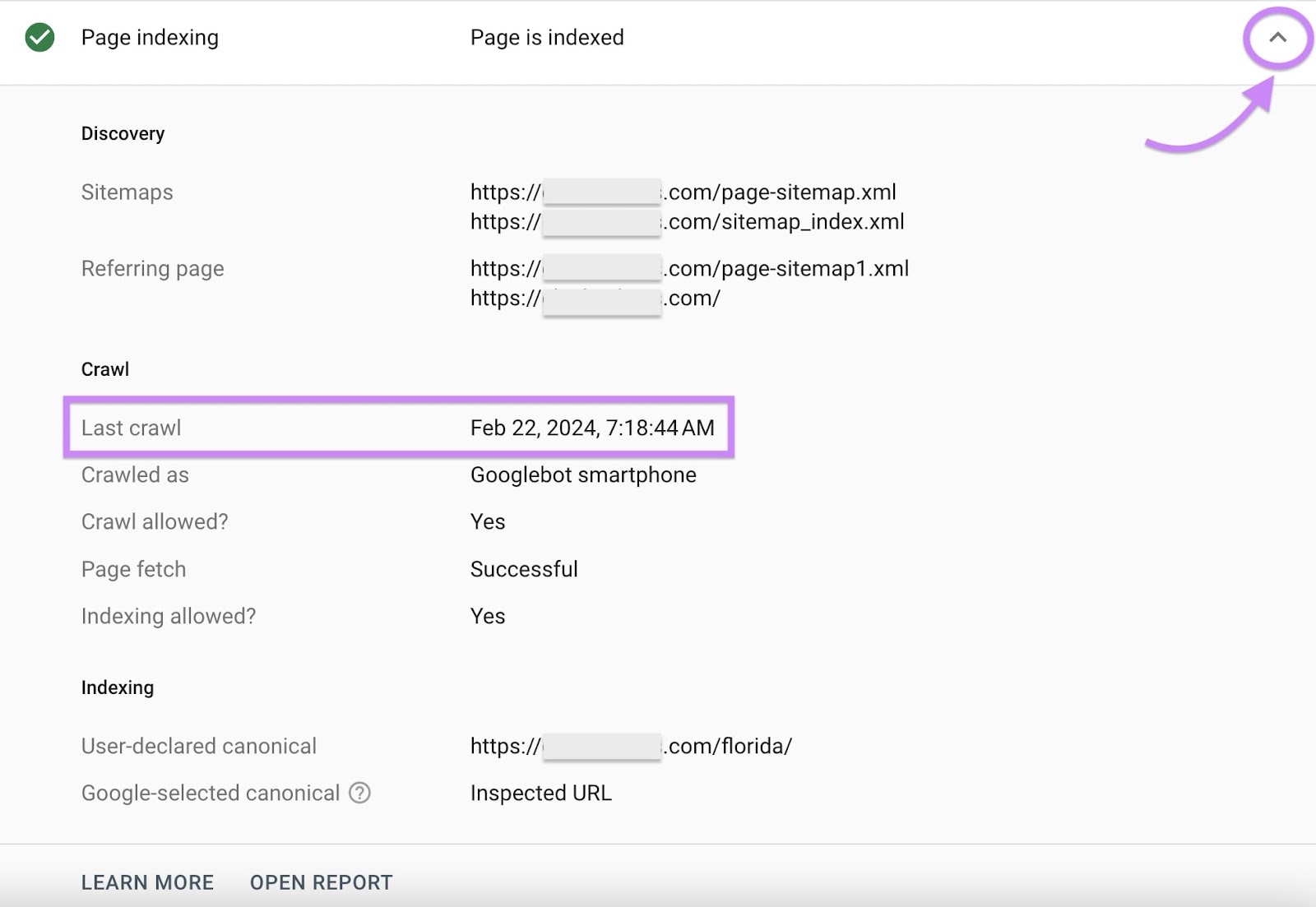
To view how Google sees your page, click “Test live URL.”
Google will test your page’s URL in real time. When the test is complete, click “View tested page” > “Screenshot.” You’ll see a section of your page’s current appearance to Google.
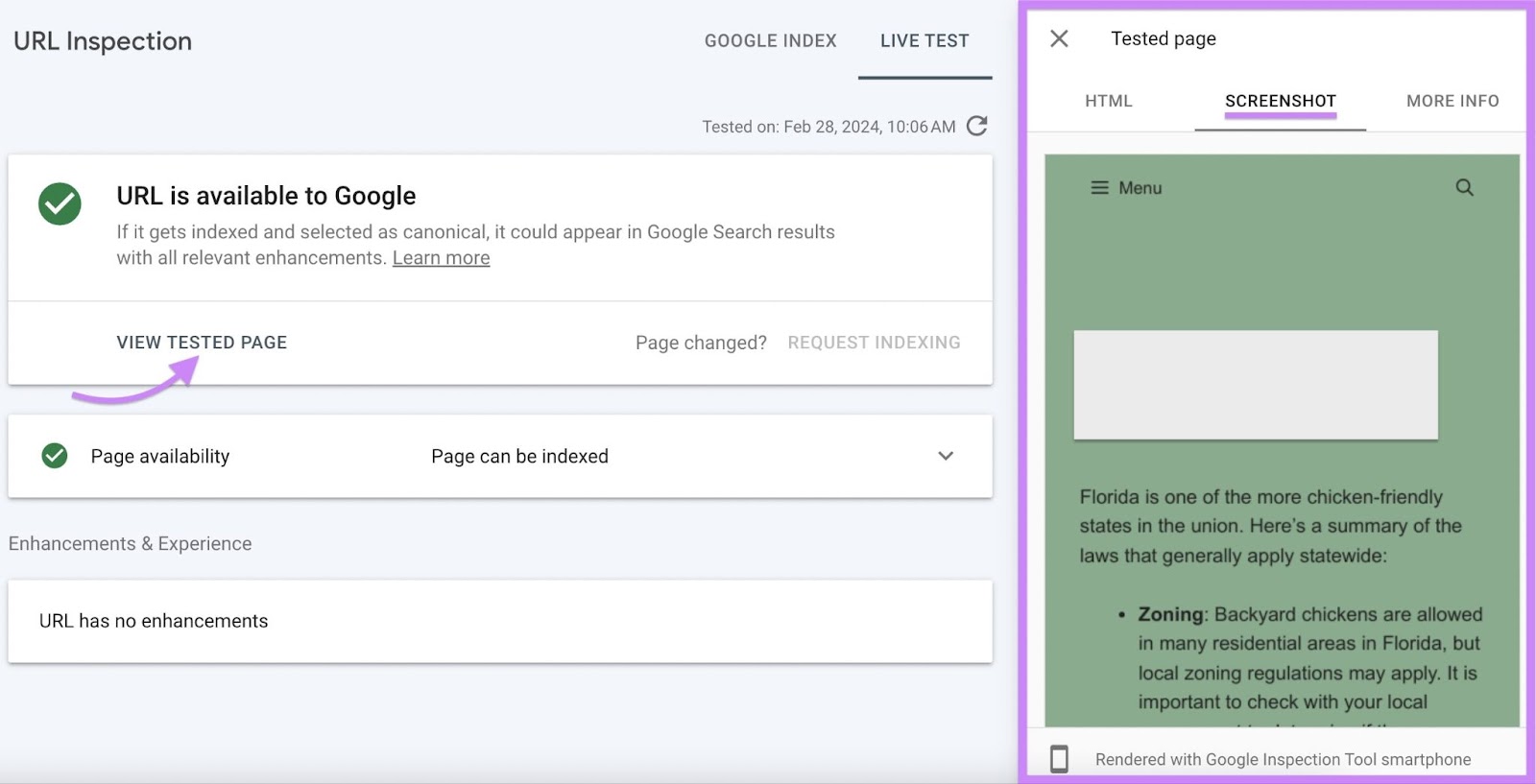
The URL Inspection Tool’s results for indexed and live URLs may differ if your page has changed since Google’s last indexing of it.
Let’s say you previously added the “noindex” tag to your page to prevent Google from indexing it. But you recently removed this tag to make your page indexable.
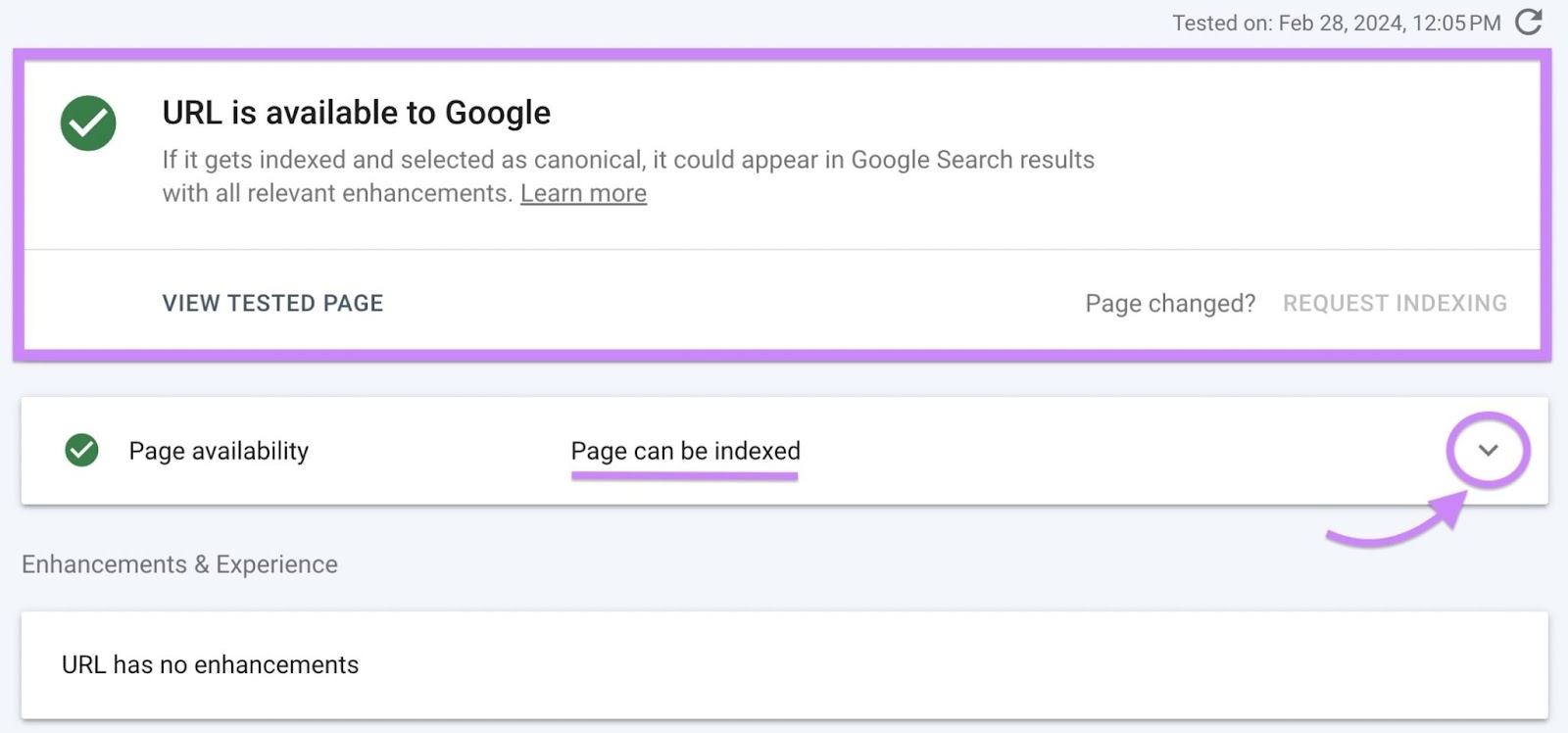
If Google hasn’t recrawled your page after this removal, it won’t have detected the change. So, the URL Inspection Tool will still report your page’s “Page indexing” status as being “Page is not indexed: URL is unknown to Google”:
But when you live-test your page’s URL, the tool will report your page’s “Page availability” status as “Page can be indexed” instead.
Rich Results Test Tool
Developed by Google, the Rich Results Test tool lets you live-test a page for rich results—special content that helps it stand out on the SERP. In the process, the tool can provide details like:
- The date and time Google last crawled the page
- Whether Google could crawl the page
- How Google saw the page when crawling it
The URL Inspection Tool offers similar information. But the Rich Results Test tool differs in these ways:
- The Rich Results Test tool crawls pages’ live URLs in real time. Unlike the URL Inspection Tool, it can’t retrieve existing page data from Google’s index.
- You can check any page URL using the Rich Results Test tool. The URL Inspection Tool limits you to checking the page URLs of websites you have admin access to.
Use the Rich Results Test tool by navigating to search.google.com/test/rich-results. Type—or copy and paste—the URL you want to test into the search bar.
Then, click “Test URL.”
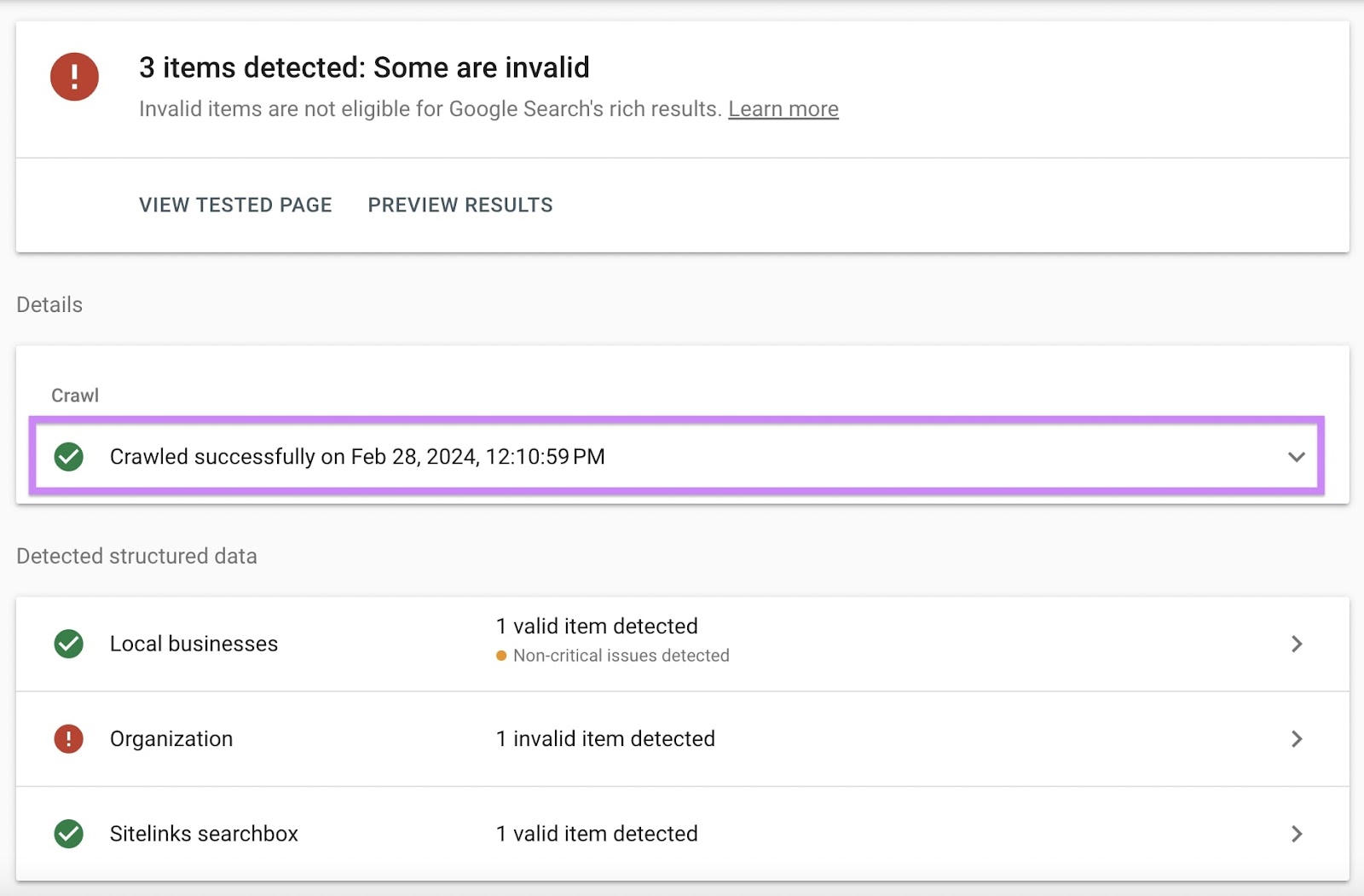
Under “Details,” you’ll see:
- Google’s crawl status for the page, e.g., “Crawled successfully” or “Crawl failed”
- The date and time of the (un)successful crawl
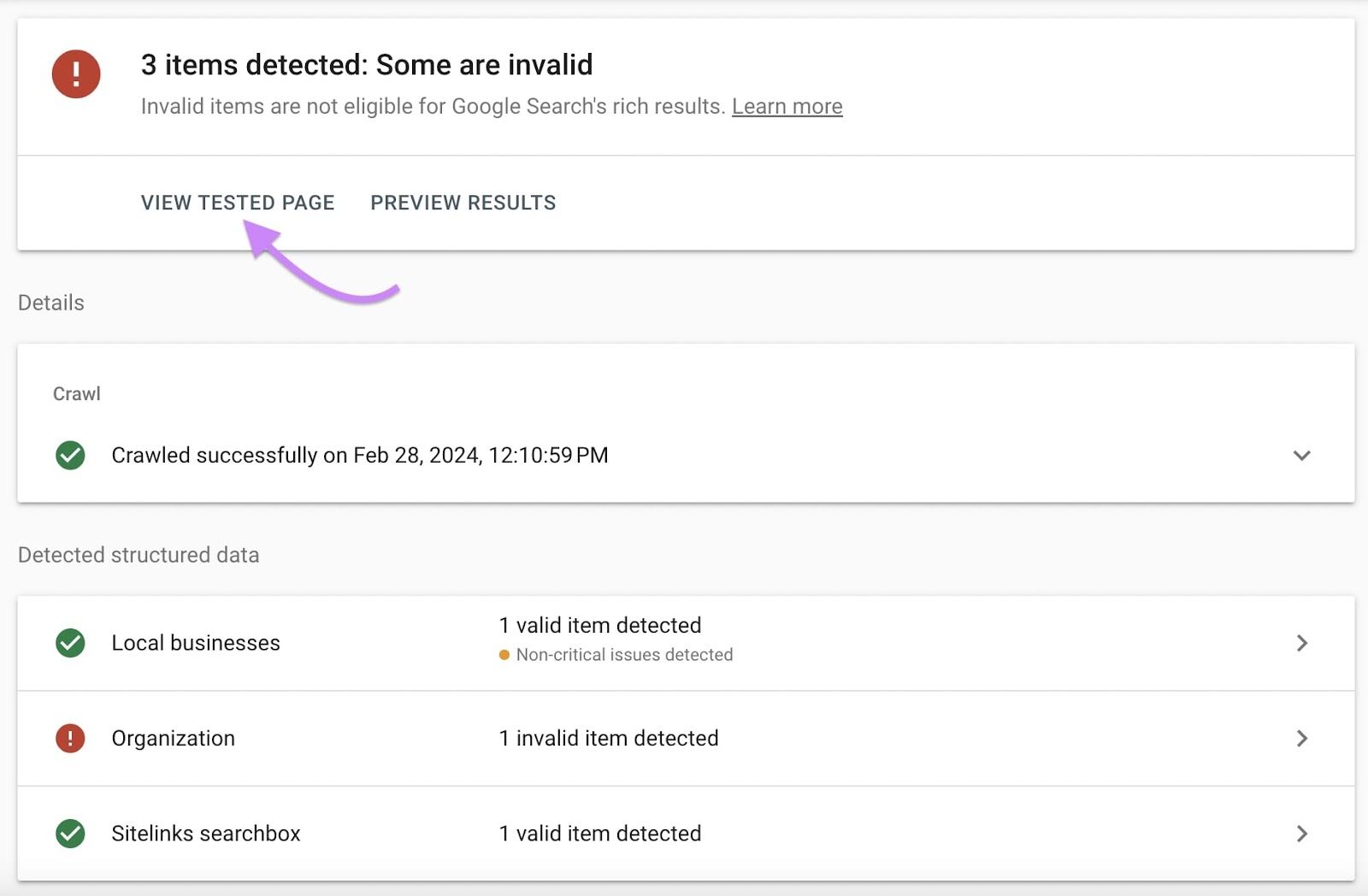
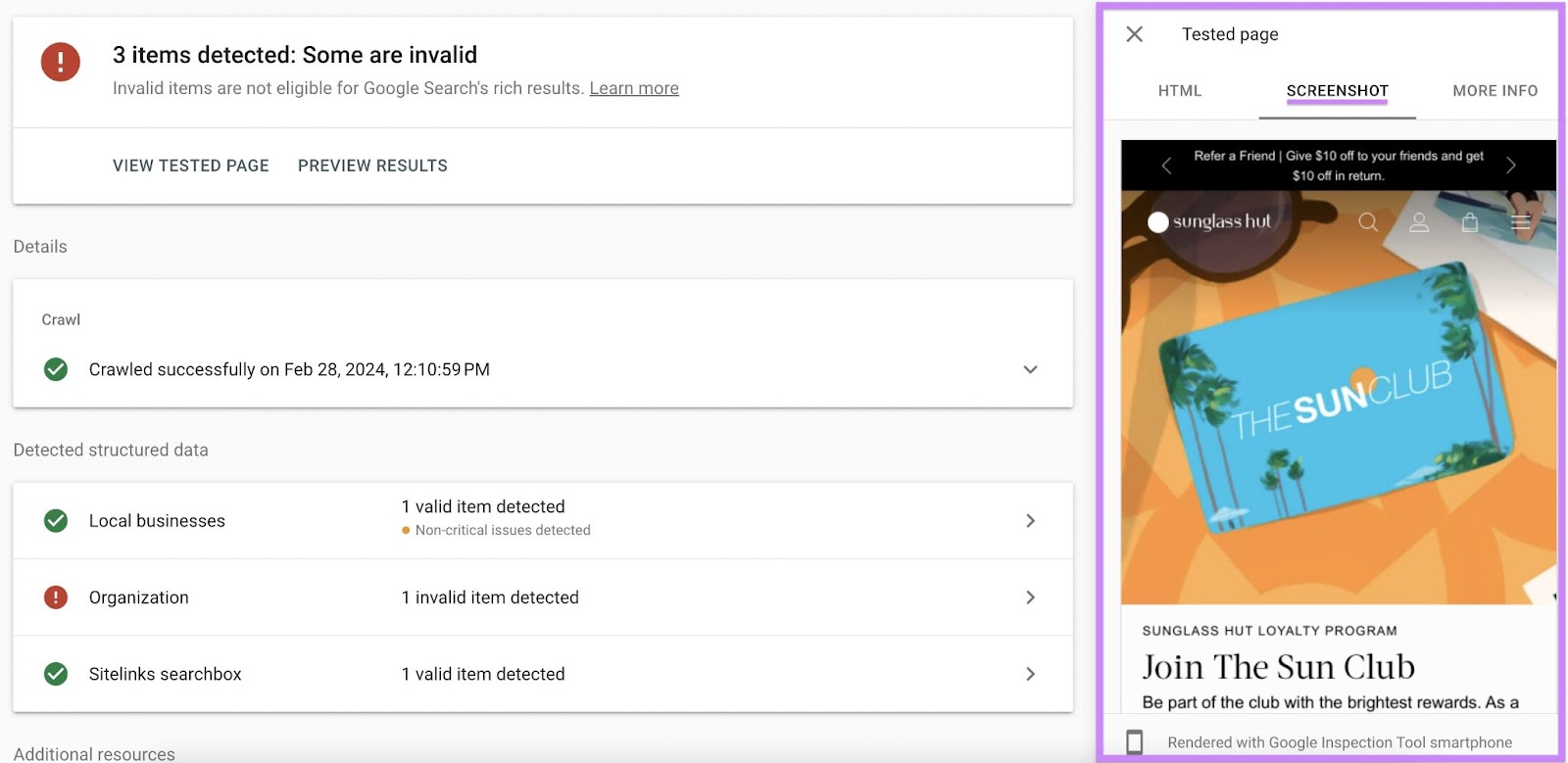
To view how Google saw your page while crawling it, click “View tested page.”
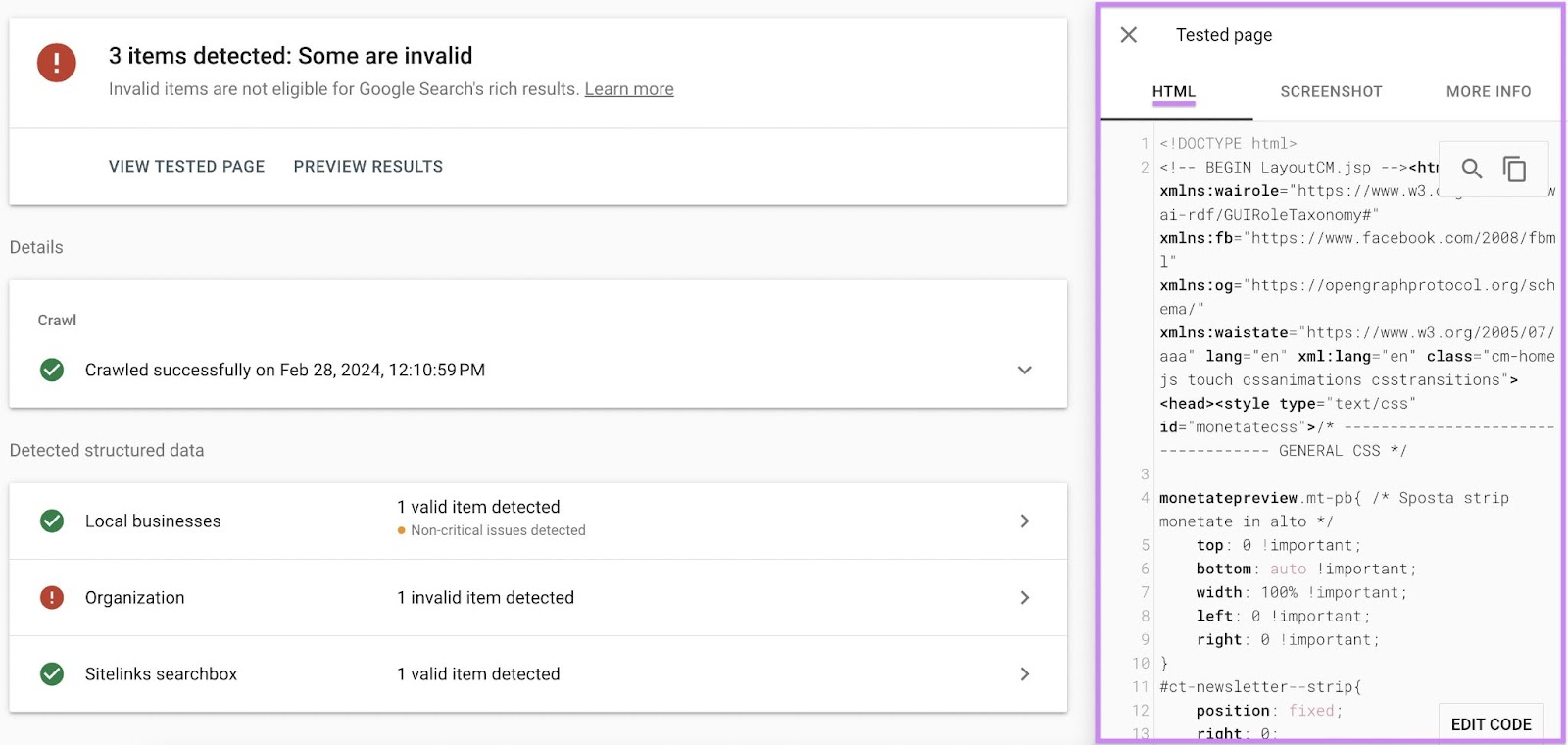
A panel will appear on the right. Its “HTML” tab shows you the HTML Google detected on the page:
Click the “Screenshot” tab to view a section of your page’s current appearance to Google.
Other Search Engines’ Caches
While Google may have disabled access to its cached pages, other search engines also cache pages. And continue to allow access to them.
These search engines include Bing and Yahoo!.
Here’s how to access a cached version of a page in Bing, for example. You’ll find the process familiar if you know how to view Google cached pages:
Navigate to Bing. Type—or copy and paste—the page’s URL into the search bar.
Locate the page’s search result on Bing’s SERP and click the downward-pointing arrow next to the page’s URL.
Then, click “Cached.”
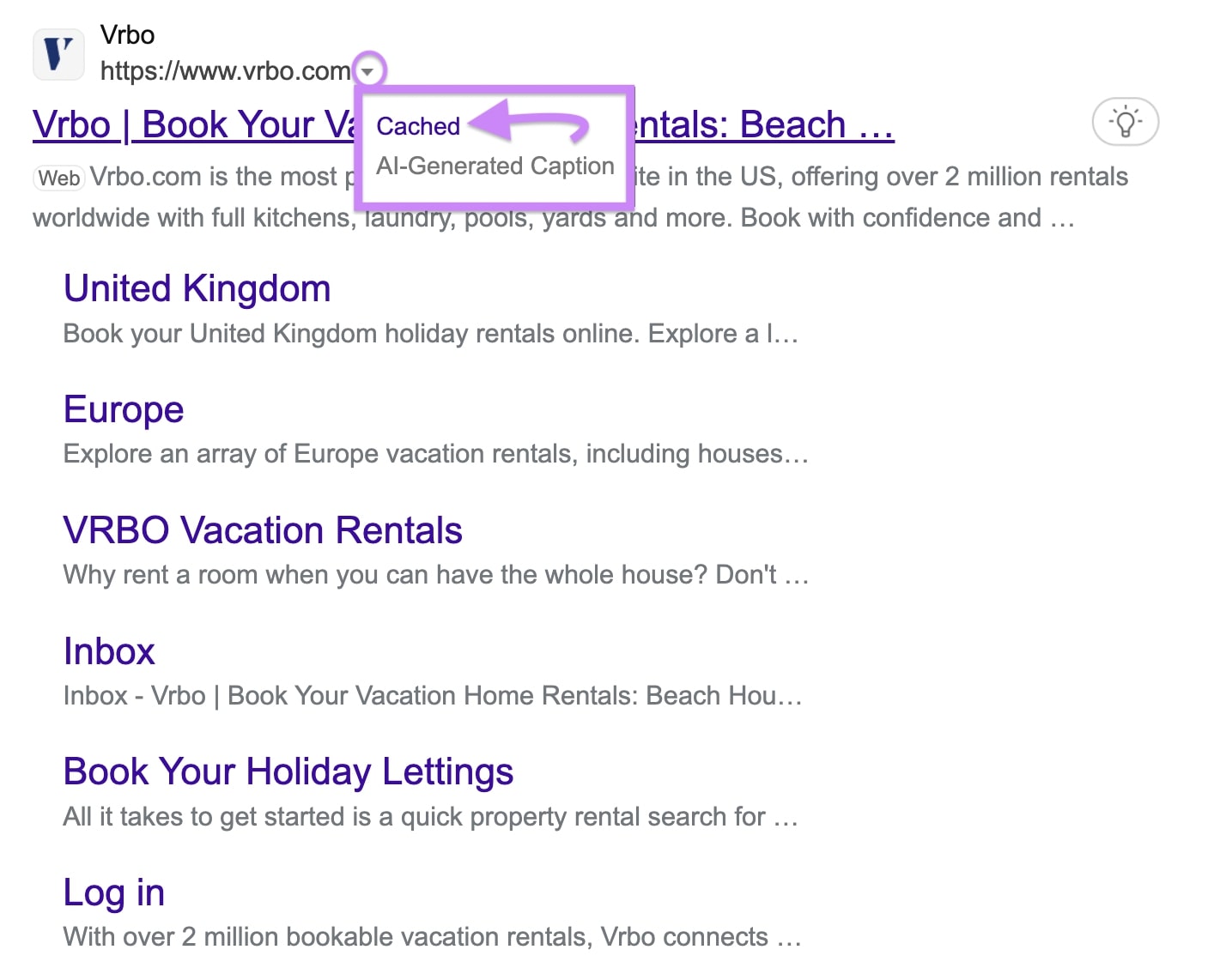
You’ll see Bing’s cached version of the page. And information on the date on which Bing created it.
Wayback Machine
Owned by Internet Archive, Wayback Machine is an online database of pages as they appeared on different dates.
It serves as a historical archive of the internet, allowing users to check how pages looked on various dates. And track the changes to them over time.
In contrast, the caches of search engines (Google or otherwise) offer only one past version of a page—the page’s appearance when they last cached it.
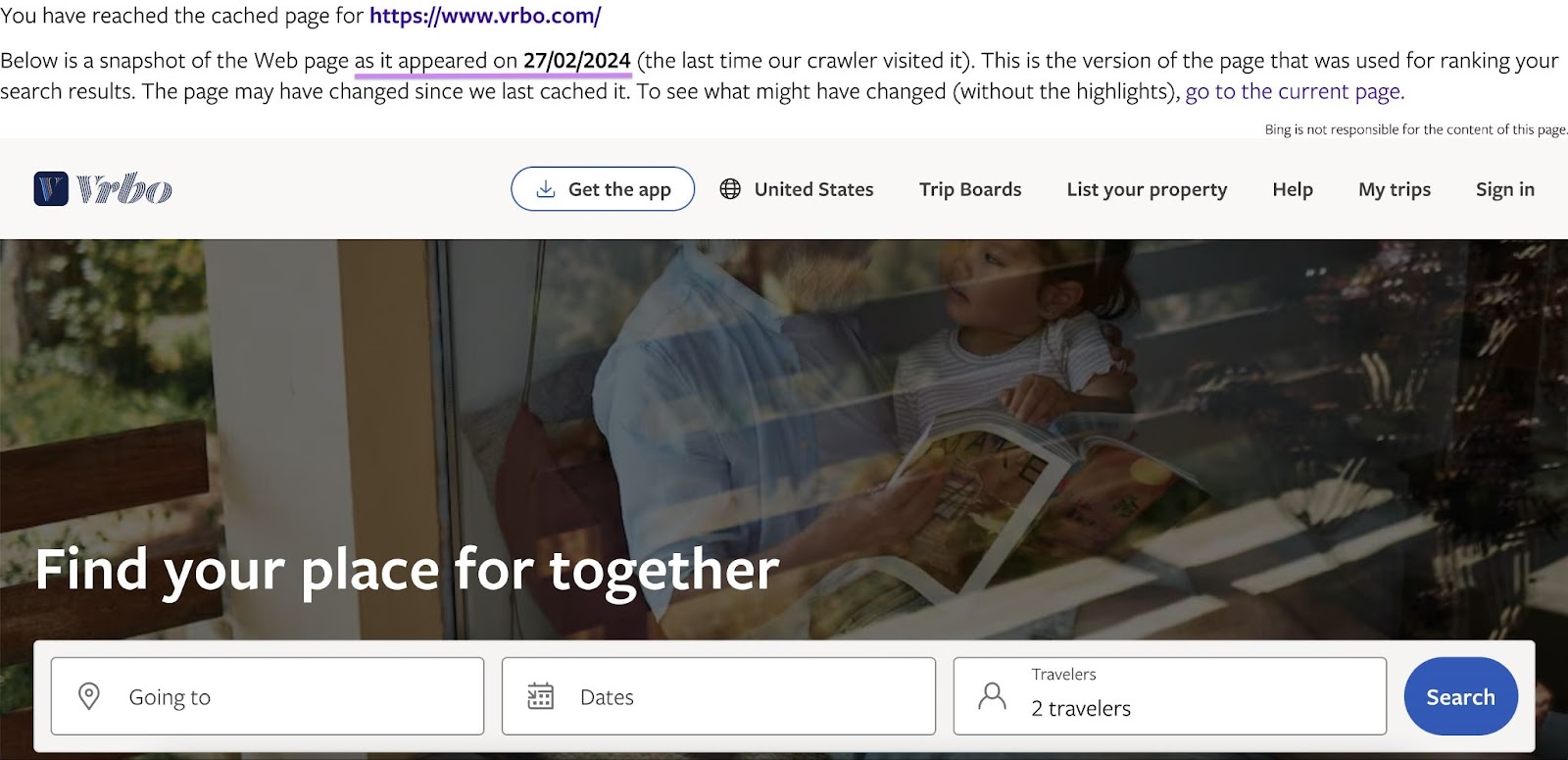
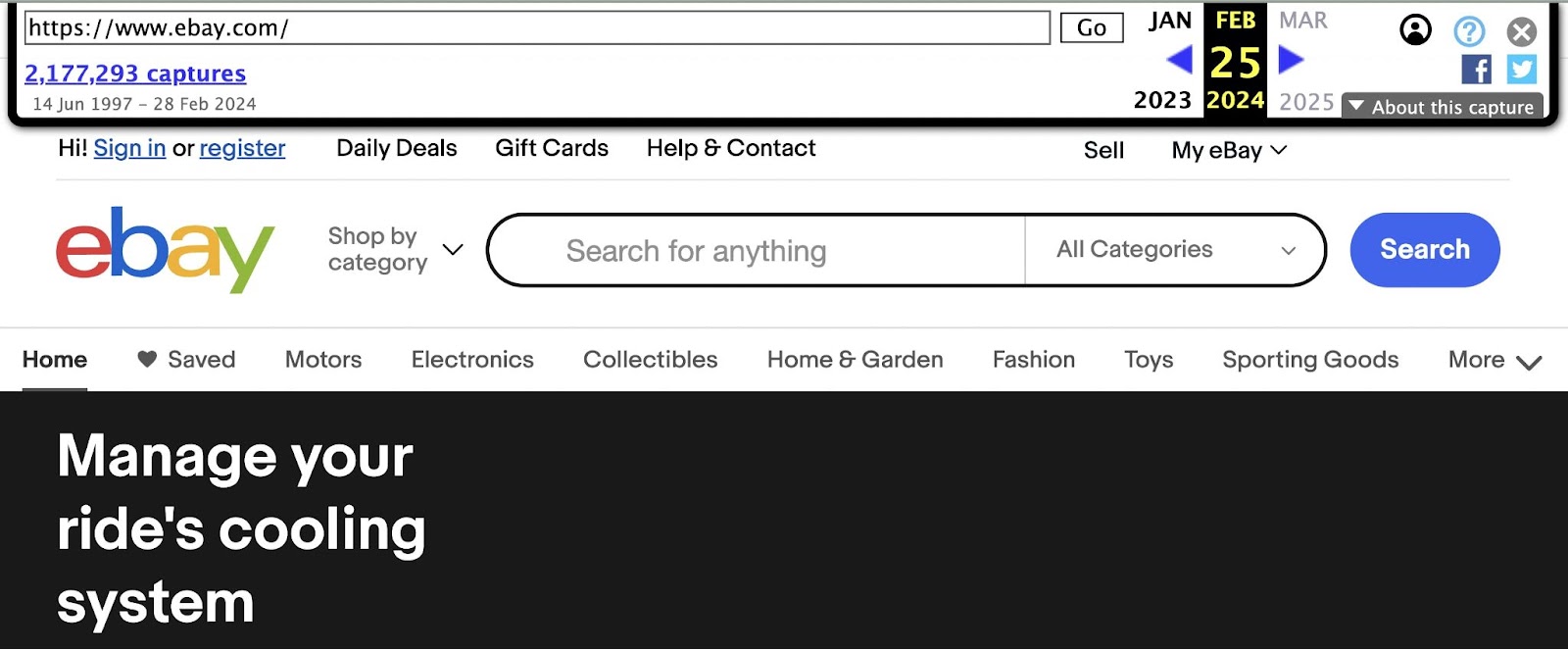
To use Wayback Machine, navigate to web.archive.org. Type—or copy and paste—a page’s URL into the search bar.
Hit “Enter” or “Return” on your keyboard to run the search.
If Wayback Machine has archived the page at least once, it’ll tell you when it first did so. And how many copies of the page it’s saved since then. Click any year in the timeline and the calendar will display the dates on which snapshots are available for that year.
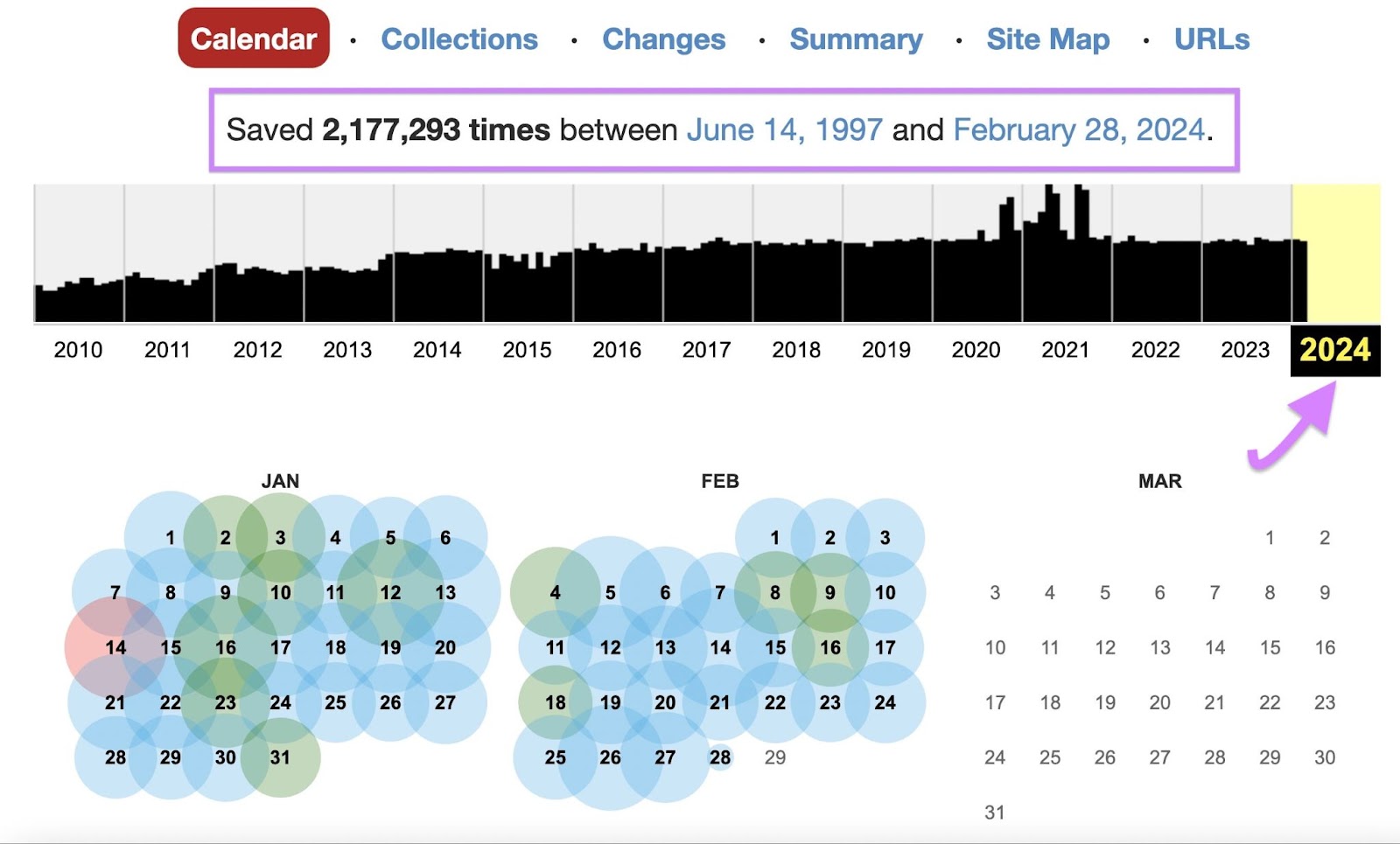
It will also display a calendar with colored circles to indicate the dates on which it has saved at least one copy—or “snapshot”—of the page.
Hover your cursor over any highlighted date to view a list of timecodes at which Wayback Machine snapshotted the page that day.
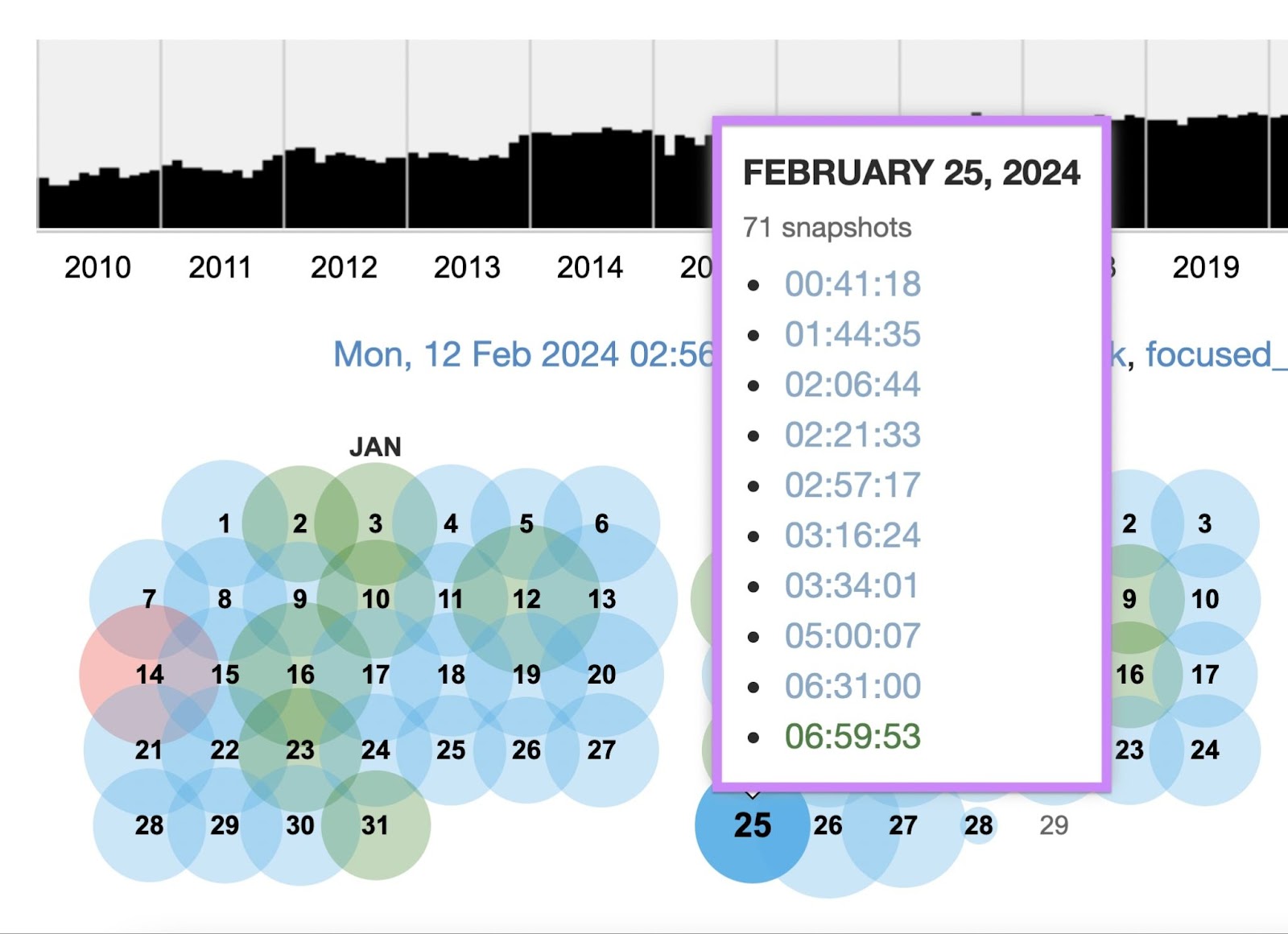
Click any timecode on the list to view its associated snapshot.
Best Practices for Webmasters in a Post-Google-Cache Era
If you run or maintain a website, take these steps to mitigate the loss of Google’s cached pages:
View Pages Using URL Inspection Tools
Instead of searching for cached pages on Google to learn how the search engine saw your pages when indexing them, use alternative tools like the URL Inspection Tool and Rich Results Test tool.
As mentioned earlier, these tools can provide more accurate insights into how Google has indexed your pages.
And, just like Google’s “cached” feature, you don’t need to connect your website to any special platform to use the Rich Results Test tool.
Ensure Your Website Loads Reliably (and Quickly)
As users now have one fewer workaround for browsing unavailable or slow webpages, it’s even more important that your website loads quickly and reliably.
Technical issues, like an overly high HTTP request count, can slow down a page’s load speed. While others, like 404 errors, can prevent it from loading at all. Use a tool like Semrush’s Site Audit to detect and fix these issues, and schedule regular checks to keep them at bay.
To use Site Audit, log in to your Semrush account and click “SEO” > “Site Audit” in the left sidebar.
Click “+ Create project.”
Fill out your website’s domain (or subdomain) and an optional project name in the “Create project” window that appears. Then, click “Create project.”
Site Audit will check your domain and its subdomains by default. If you don’t need it to check your subdomains, click the pencil icon next to the “Crawl scope” setting.
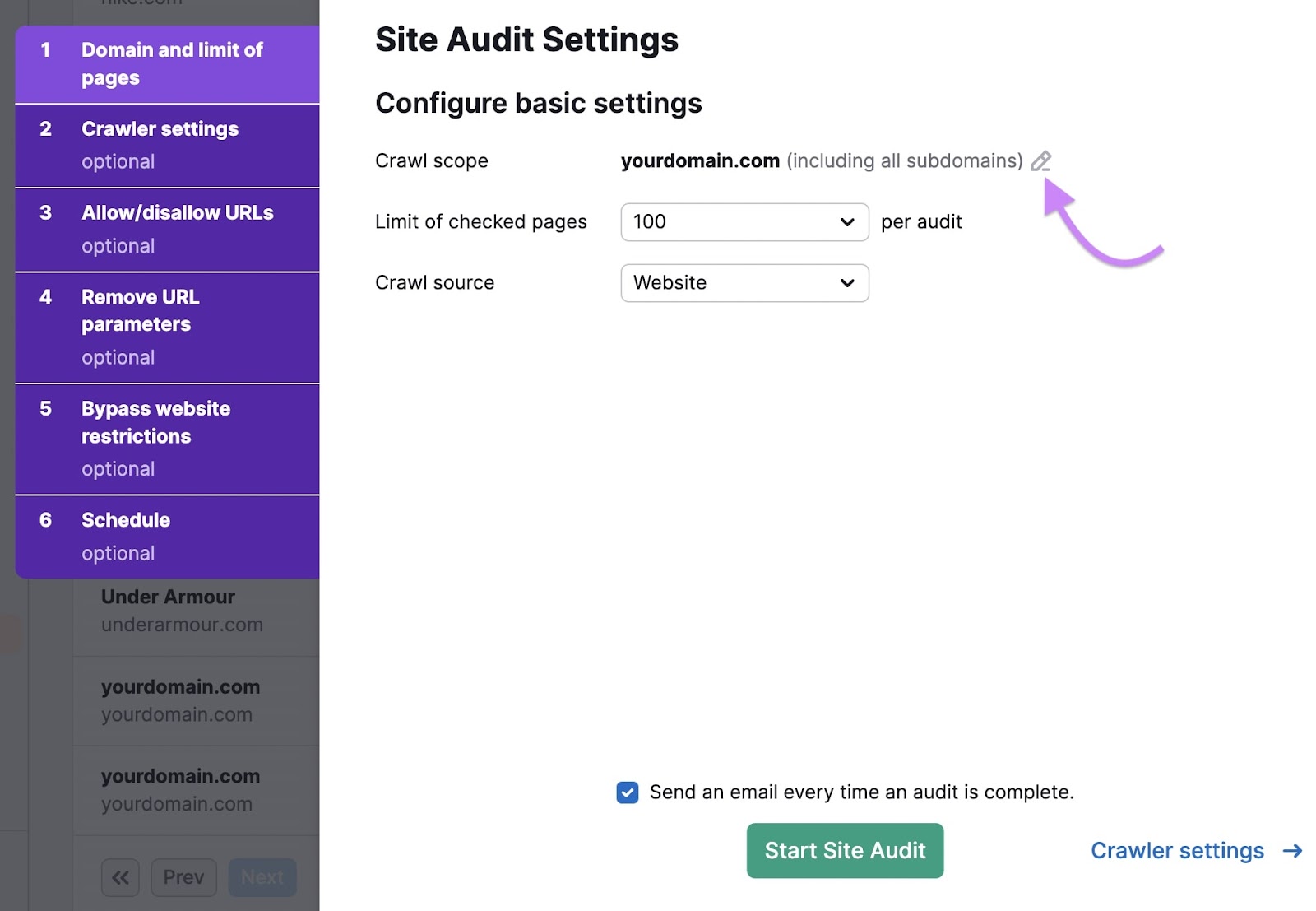
Uncheck the “Crawl all subdomains of [domain]” checkbox, and then click “Save changes.”
![“Crawl all subdomains of [domain]” checkbox in Site Audit Settings](https://static.semrush.com/blog/uploads/media/98/18/9818c8213a884d1d16fd60c5250ee6ab/fbb44ae0ce283dbc96f54b1f94cea8f7/QlF1P-SCxF_P3ZLkwGp9DnY3HUAD4tGJHVANA9eFSLMJ9_G7dx-PWxehYQKPbSPRY31yXp4Xdaw0KGoyGToNgZuHVWkoG8ugs25iafzbyKfGDN2Y56yY9wmENr02KY3gExj6jX5NyStJFg13CdXHDoY.jpeg)
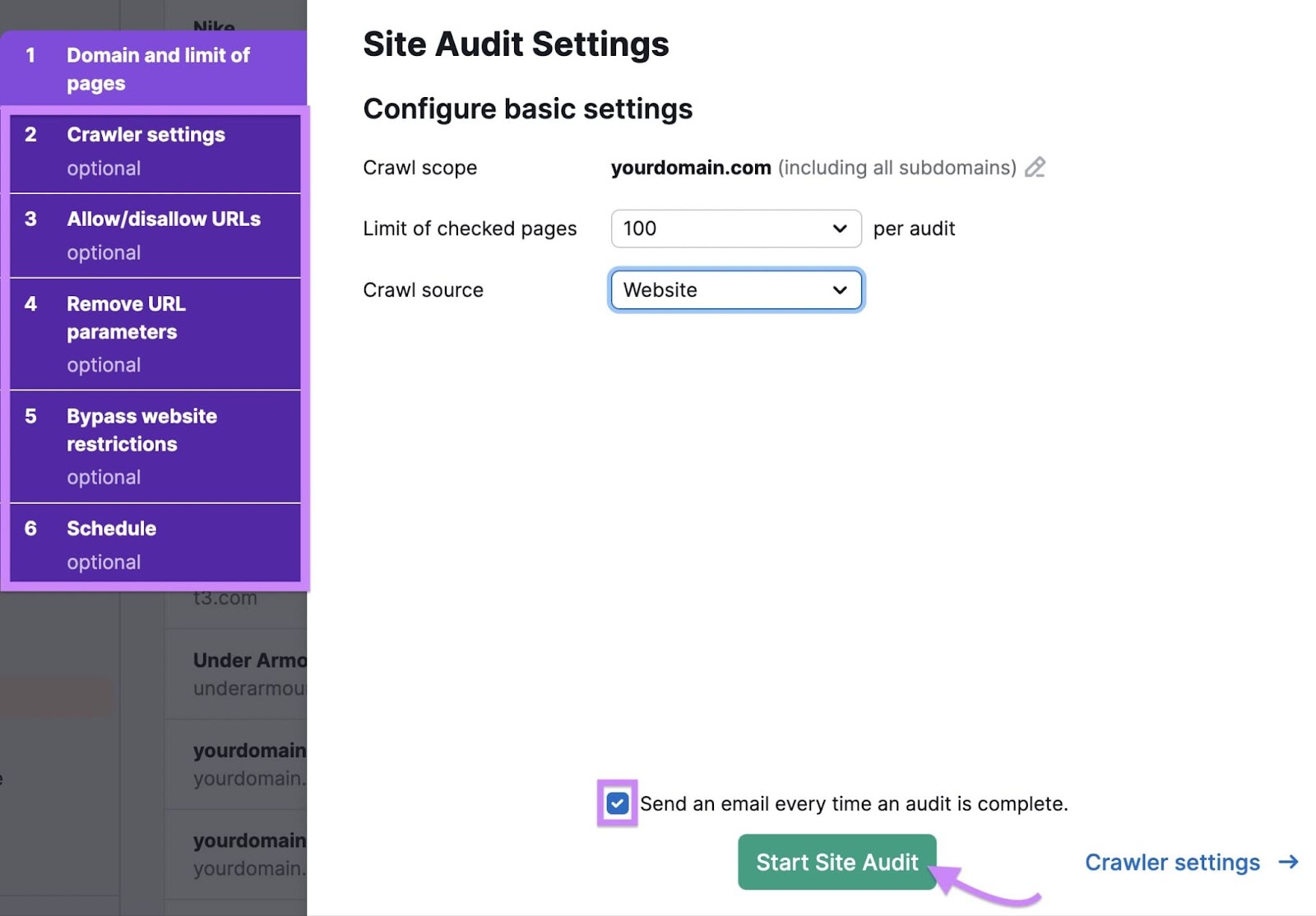
Next, use the “Limit of checked pages” setting to set up the number of pages Site Audit should check every time it runs. For example, set the limit to “100” if you want to test the tool before running it on all your webpages.
Leave the “Crawl source” setting as “Website” to have Site Audit check your entire website.
By default, Site Audit will email you to let you know when it has finished checking your website. If you don’t need this notification, uncheck the “Send an email every time an audit is complete.” checkbox.
Optional: Use the tabs numbered two to six on the left to adjust settings like:
- The URLs Site Audit should (or should not) check
- The URL parameters the tool should ignore
Click “Start Site Audit” when you’re done.
Site Audit will scan your website for issues. After it has finished its checks, click your (sub)domain in your list of projects to view the full report.
Click the “Issues” tab.
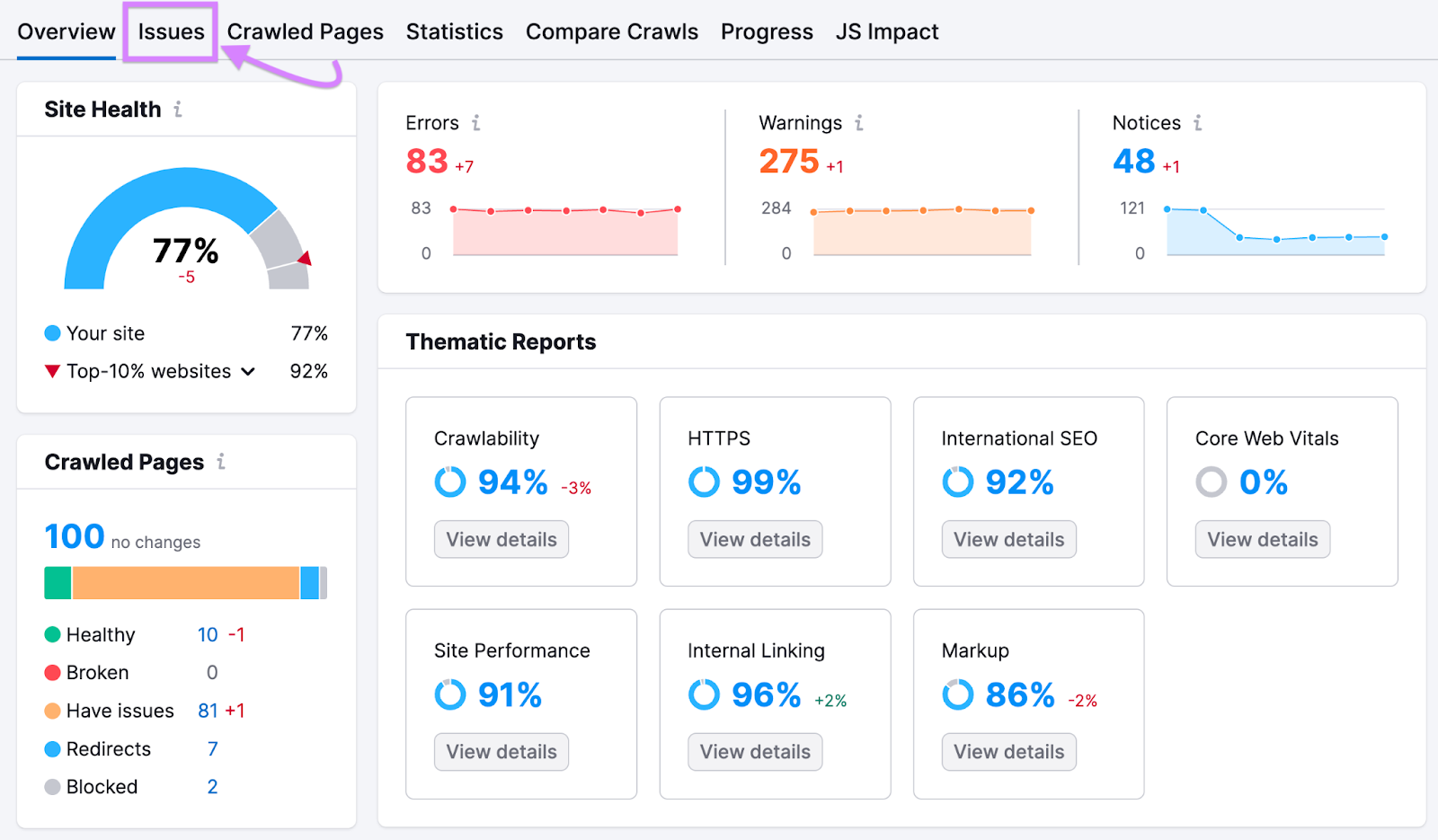
You’ll get a list of:
- Errors: The most serious issues that need urgent fixing
- Warnings: Issues that aren’t as serious but may still deserve attention
- Notices: The least serious issues that you may consider fixing
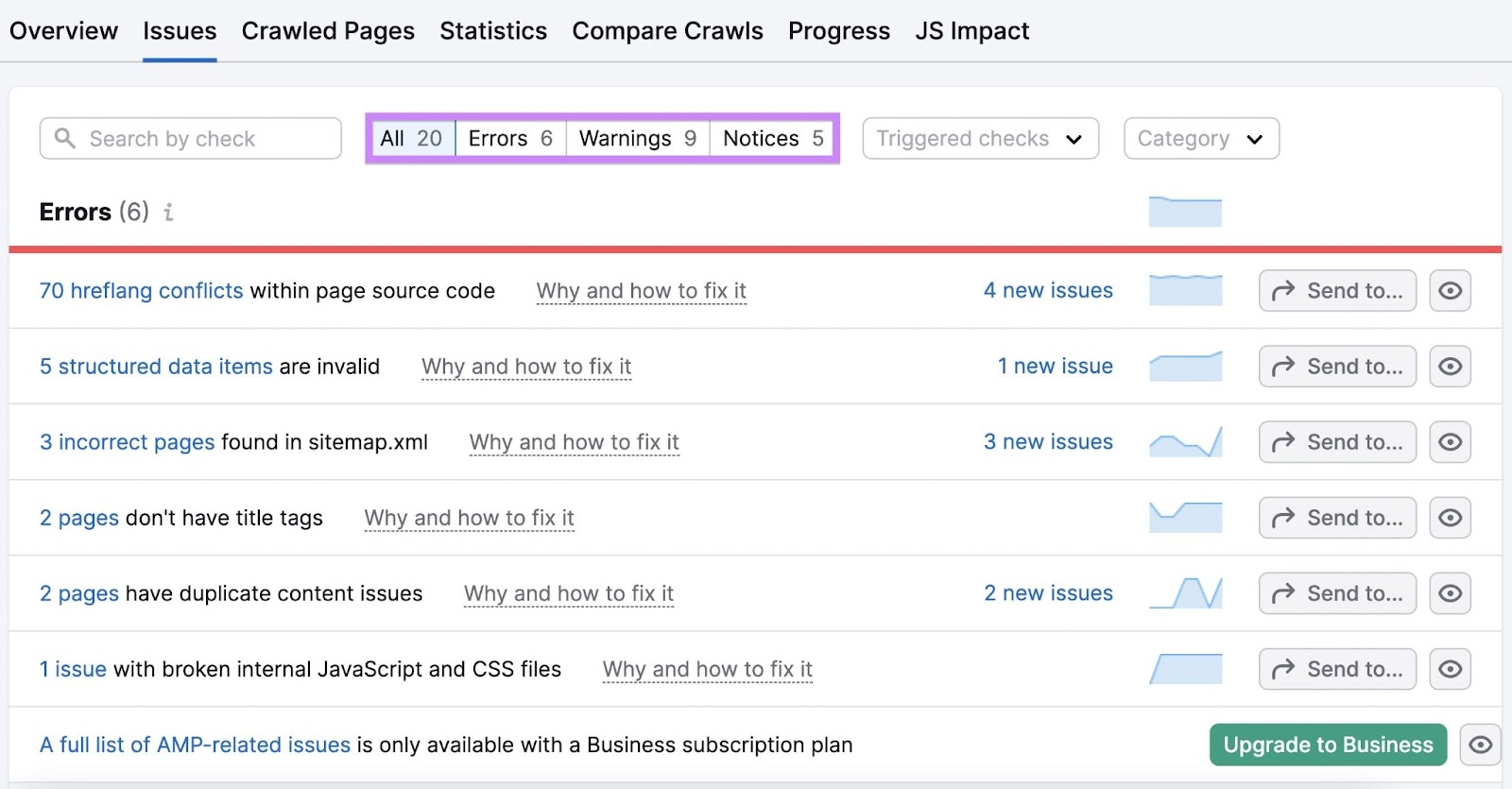
Site Audit can detect over 140 technical issues in all. In particular, look out for these errors. They may impact your website’s loading ability and speed:
- “# pages returned 4XX status code”: These pages have a 4XX error—like a 404 error—preventing users from accessing them
- “# pages couldn’t be crawled (DNS resolution issues)”: These pages have Domain Name System (DNS) errors that prevent Site Audit from accessing the server on which they’re hosted. In this case, users likely can’t view them either
- “# pages have slow load speed”: These pages take a long time to load
Click the hyperlinked “# pages” text for any of these errors to see the pages experiencing them.
For example, here’s what you’ll see when you click to view the pages that returned 4XX status codes:
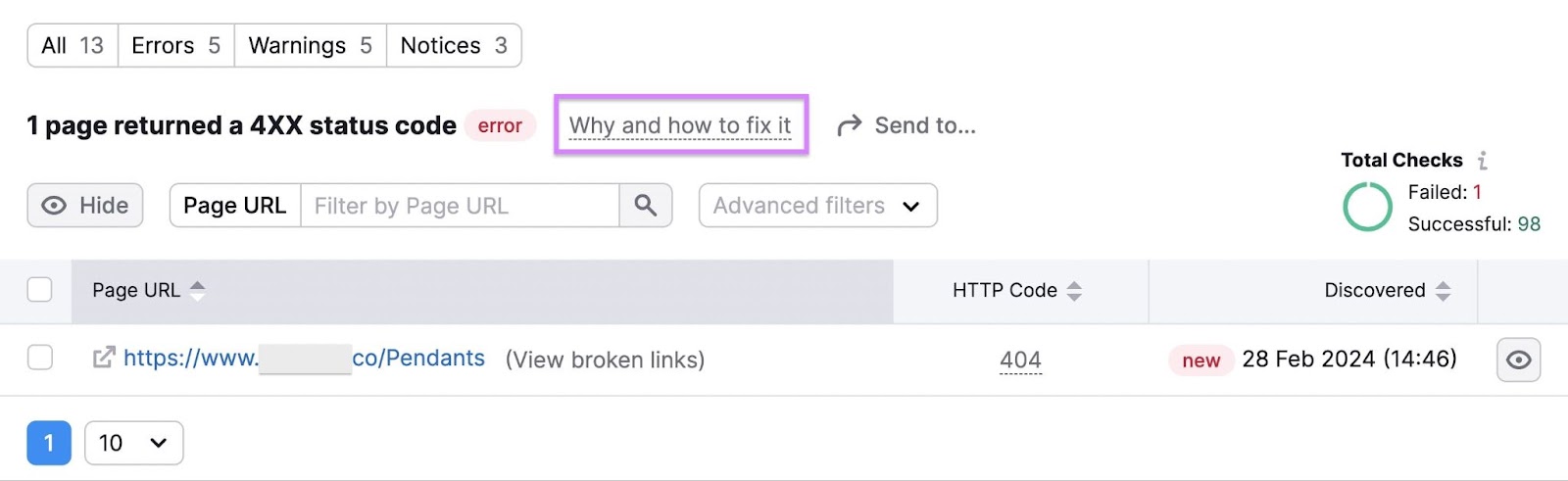
Then, address the detected issues. Click the “Why and how to fix it” text next to each error to get guidance on fixing it.
These articles may also be useful:
If in doubt, contact a web developer for help.
Site Audit can also scan your website regularly. So you stay on top of any new issues that crop up.
Click the gear icon at the top of the Site Audit report. Scroll down the list of settings under “Site Audit settings” and click “Schedule: Weekly, Every Tuesday,” (or whatever day it is you’re looking at this report).
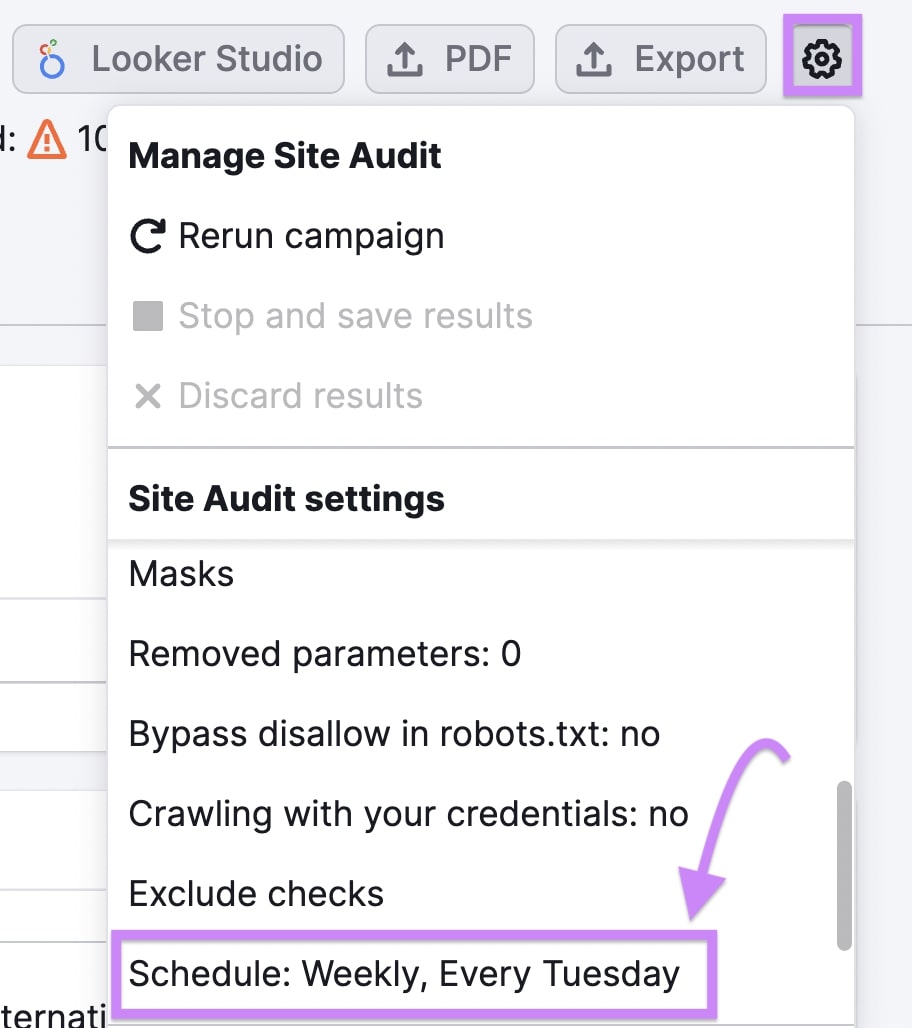
Choose whether Site Audit should scan your website daily, weekly, or monthly. Then, click “Save” to set up your automatic scan schedule.
The Future of Web Content Preservation
With the discontinuation of Google’s “cached” feature, internet archival platforms like Wayback Machine may play a larger role in preserving a historical record of the web.
Why?
Because these platforms document changes to a page’s content over time. Unlike other search engines’ caches, which only let users view the latest version of a cached page.
Wayback Machine stands to become an even more prominent archival service if it gets an official tie-up with Google.
Although he makes no promises at this time, Google’s Danny Sullivan has expressed interest in replacing the search engine’s cached links with links to Wayback Machine:
Personally, I hope that maybe we’ll add links to [Wayback Machine] from where we had the cache link before, within About This Result. It’s such an amazing resource. For the information literacy goal of About The Result, I think it would also be a nice fit — allowing people to easily see how a page changed over time. No promises. We have to talk to them, see how it all might go — involves people well beyond me. But I think it would be nice all around.
How to Prevent Caching
Although Google’s “cached” feature is going away, other platforms like Bing and Wayback Machine may still cache your pages.
Try these options if you don’t want them to.
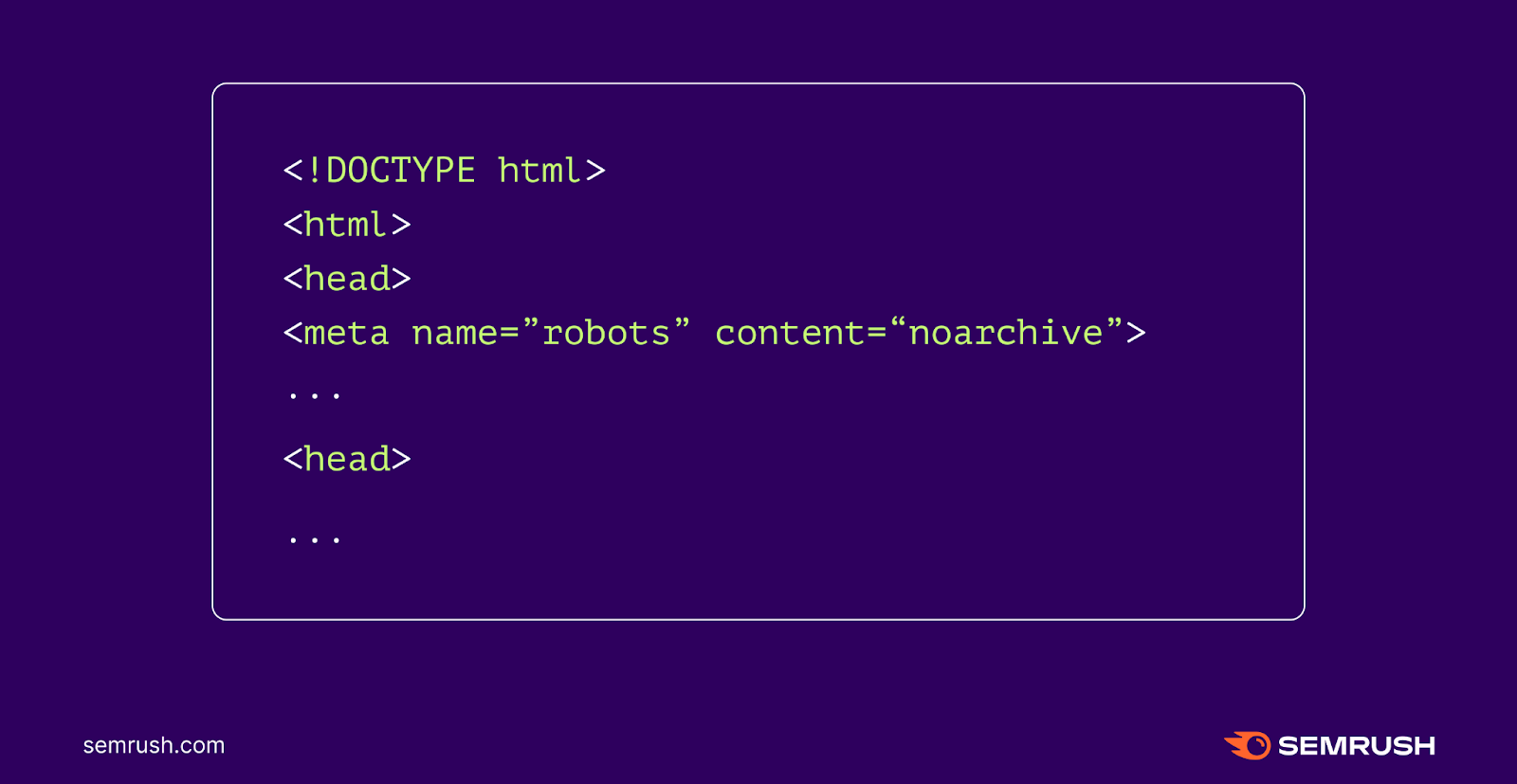
Use the ‘Noarchive’ Meta Robots Tag
The “noarchive” meta robots tag is a code snippet you can add to a page to tell a platform not to cache it. As a result, users won’t be able to access a cached version of the page.
The tag looks like this:
<meta name="robots" content="noarchive">
Add this tag to the <head> section of every page you want to keep out of others’ caches. Like so:
Submit a Request Not to Be Cached
Some platforms provide a formal procedure for opting out of their cache. If so, follow it even if you’ve already added the “noarchive” tag to your pages.
That’s because the platform may not check for the “noarchive” tag when caching your pages. Alternatively, it may exclude your pages from its cache only when you make a formal request.
To request that Wayback Machine doesn’t cache your pages, for example, send an email to info@archive.org with information like:
- The page URL(s) you don’t want Wayback Machine to cache
- The period for which the platform shouldn’t cache your pages
Wayback Machine will review your request and decide whether to agree to it.
No Google Cached Pages? No Problem
Even though we have to say goodbye to Google’s cached pages, there are alternatives for its various functions.
For example, there’s the URL Inspection Tool and Rich Results Test tool if you want to check how Google saw your pages when indexing them.
And if users have trouble loading your page, they can check its cached version in other search engines’ caches or on Wayback Machine.
That said, it’s best if users can reliably access your website in the first place.
Semrush’s Site Audit provides monitoring of your website for technical issues. So you become aware of—and can promptly fix—those that keep users from accessing your website.
Try Site Audit by signing up for a free Semrush account.